1. Standard Reports
Typically generated on a regular basis, standard reports describe what happened in a particular area.
They answer the questions “What happened?” and “When did it happen?”. They are not useful in
making long-term decisions. Examples include monthly or quarterly financial reports.
2. Ad Hoc Reports
Generally, ad hoc reports let you ask questions and request a custom report to find the answers.
They answer the questions “How many?”, “How often?”, and “Where?”. A custom report that
describes direct marketing campaign performance is an example of this type of report.
3. Query Drilldown or On-Line Analytical Processing (OLAP)
Query drilldown allows for some discovery. OLAP lets you manipulate the data to find out how
many, what geography, what class year, what gift level, etc. Query drilldown and OLAP answer the
questions “What exactly is the problem?” and “How do I find the answers?”. An example of this is
sorting and exploring data about different types of donors and their annual giving behavior.
4. Alerts or Triggers
With alerts or triggers, you can learn when you have a problem or opportunity and be notified when
something similar happens again in the future. Alerts can appear via email, as a flag within the
software, or as red dials on a scorecard or dashboard. They answer the questions “When should I
react?” and “What actions are needed now?”. An example of an alert or trigger would be an email to
a gift officer indicating that a donor prospect just received a windfall from the sale of his company.
5. Statistical Analysis
With statistical analysis, nonprofits use more complex analytics, like frequency models and
regression analysis. We begin to look at why things are happening using donor behavior data and
then begin to answer questions based on the data. Statistical analysis answers the questions “Why
is this happening?” and “What opportunities am I missing?”. A nonprofit discovering where upgrade
opportunities exist in their active donor file is an example of an organization using statistical analysis. 6. Forecasting
Forecasting is one of the most useful analytical applications, as it enables effective resource
and budget allocation. It answers the questions “What if these trends continue?”, “How much is
needed?”, and “When will it be needed?”. As an example, nonprofits can use forecasting to predict
how declining acquisition response rates will affect their overall fundraising goals, enabling budget
allocation and strategy refinement.
7. Segmentation or Descriptive Data
Descriptive data uses donor attributes to describe donor behavior or classify donors into groups.
Generally, it uses historical behavior to classify individuals, enabling future treatment strategies. It
answers the questions “What group or classification does this individual belong to?” and “What
characteristics does this individual have?”. Examples of segmentation or descriptive data include
address, age, income, marital status, presence of children in household, and recent donation amount.
8. Predictive Modeling
Predictive modeling analyzes historical and comparative data about donors to predict a future
behavior. It answers the questions “What will happen next?” and “How will it affect my business?”.
Examples of predictive modeling include likelihood to respond to a direct mail solicitation, likelihood
to leave a bequest, and likelihood to give a principal gift.
9. Decision Support System (DSS) or Prescriptive Analytics
Prescriptive analytics synthesizes data to make predictions and then suggests options to take
advantage of the prediction. It describes what you should do and prompts a specific action.
Examples include suggesting a target ask amount and prompting a nonprofit to remove a deceased
donor from the file.
10. Optimization
Optimization supports innovation. It takes your resources and needs into consideration and helps
you find the best possible way to accomplish your goals, answering the questions “How do we
do things better?” and “What is the best decision for a complex problem?”. An example using
optimization would be: Given business priorities, budget constraints and available technology, what
is the best way to optimize our marketing spend to meet our annual fund objective?
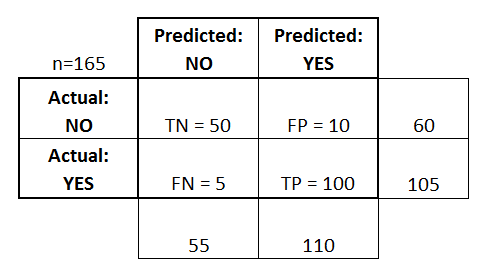
A confusion matrix is a table that is often used to describe the performance of a classification model (or "classifier") on a set of test data for which the true values are known. The confusion matrix itself is relatively simple to understand, but the related terminology can be confusing.
I wanted to create a "quick reference guide" for confusion matrix terminology because I couldn't find an existing resource that suited my requirements: compact in presentation, using numbers instead of arbitrary variables, and explained both in terms of formulas and sentences.
Let's start with an example confusion matrix for a binary classifier (though it can easily be extended to the case of more than two classes):
What can we learn from this matrix?
There are two possible predicted classes: "yes" and "no". If we were predicting the presence of a disease, for example, "yes" would mean they have the disease, and "no" would mean they don't have the disease.
The classifier made a total of 165 predictions (e.g., 165 patients were being tested for the presence of that disease).
Out of those 165 cases, the classifier predicted "yes" 110 times, and "no" 55 times.
In reality, 105 patients in the sample have the disease, and 60 patients do not.
Let's now define the most basic terms, which are whole numbers (not rates):
true positives (TP): These are cases in which we predicted yes (they have the disease), and they do have the disease.
true negatives (TN): We predicted no, and they don't have the disease.
false positives (FP): We predicted yes, but they don't actually have the disease. (Also known as a "Type I error.")
false negatives (FN): We predicted no, but they actually do have the disease. (Also known as a "Type II error.")
I've added these terms to the confusion matrix, and also added the row and column totals:
This is a list of rates that are often computed from a confusion matrix for a binary classifier:
Accuracy: Overall, how often is the classifier correct?
(TP+TN)/total = (100+50)/165 = 0.91
Misclassification Rate: Overall, how often is it wrong?
(FP+FN)/total = (10+5)/165 = 0.09
equivalent to 1 minus Accuracy
also known as "Error Rate"
True Positive Rate: When it's actually yes, how often does it predict yes?
TP/actual yes = 100/105 = 0.95
also known as "Sensitivity" or "Recall"
False Positive Rate: When it's actually no, how often does it predict yes?
FP/actual no = 10/60 = 0.17
Specificity: When it's actually no, how often does it predict no?
TN/actual no = 50/60 = 0.83
equivalent to 1 minus False Positive Rate
Precision: When it predicts yes, how often is it correct?
TP/predicted yes = 100/110 = 0.91
Prevalence: How often does the yes condition actually occur in our sample?
actual yes/total = 105/165 = 0.64
A couple other terms are also worth mentioning:
Positive Predictive Value: This is very similar to precision, except that it takes prevalence into account. In the case where the classes are perfectly balanced (meaning the prevalence is 50%), the positive predictive value (PPV) is equivalent to precision.
Null Error Rate: This is how often you would be wrong if you always predicted the majority class. (In our example, the null error rate would be 60/165=0.36 because if you always predicted yes, you would only be wrong for the 60 "no" cases.) This can be a useful baseline metric to compare your classifier against. However, the best classifier for a particular application will sometimes have a higher error rate than the null error rate, as demonstrated by the Accuracy Paradox.
Cohen's Kappa: This is essentially a measure of how well the classifier performed as compared to how well it would have performed simply by chance. In other words, a model will have a high Kappa score if there is a big difference between the accuracy and the null error rate.
F Score: This is a weighted average of the true positive rate (recall) and precision.
ROC Curve: This is a commonly used graph that summarizes the performance of a classifier over all possible thresholds. It is generated by plotting the True Positive Rate (y-axis) against the False Positive Rate (x-axis) as you vary the threshold for assigning observations to a given class.
Marketing data: Product behavior, historical campaign data
Additional: Donation, donor, or household-level data
All of this data is used to understand the relationship between the two variables. Finding the model and determining its accuracy is what the predictive modeling process is all about. This process often requires several iterations and the quality of the model requires an understanding of the organization problem and the data, modeling algorithms and parameters, software, and implementation practices.
Best Practices
Before getting started with predictive analytics it’s important to understand the pieces that must all come together to ensure success. We’ve defined these below:
Define a Clear Objective: Decide what your objective is. Do you want to activate prospects? Increase donor value? Be clear on this before diving into any data.
Validate Existing Data Sets: It may sound obvious but make sure you are working with data sets that are reliable and offer meaningful results. Inaccurate data leads to inaccurate outcomes.
Upskill Your Team: Ensure your team is trained on how predictive analytics works and fundamental concepts such as A/B testing, data cleaning methods, etc. Or, work with outsourced experts who know.
Invest in Technology and Expertise: Onboarding a full-service advanced analytics solution, like Lityx, Salesforce Einstein empowers every level of your team with the capacity for predictive analytics, optimization, and automation.
Add the Right Tools: Ensure that your database, CRM, marketing automation systems, and email systems are optimized and integrate with the predictive analytics platform.
Get Team Buy-In: Make sure your entire team, especially senior management, is committed to a data-driven culture and marketing approach.
Benchmark & Measure: Define key metrics, such as donor lifetime value, conversion rates, etc. Measure these regularly to begin to understand the actionable data that comes from predictive analytics.
With prescriptive analytics, you are combining and analyzing data to make a prediction, then creating options to take advantage of that prediction. Prescriptives use the prediction to prescribe what should be done.
Imagine using your donor data not to just report what has happened, but to predict what is likely to happen. That is the opportunity offered by predictive analytics—revealing the likelihood of a major gift or a planned gift. Predictive analytics can light the way. What does the journey down that path look like?
Let’s begin with your data. Is it good?
The common concern is that the data may not be good enough to be used for an analytic effort. Whether you are using an analytic partner or using analytic software, the hygiene of your data is critical. The statistical models work from your data, and technology in use merely enables that process. The accuracy of the data determines the accuracy of the result. Cleaning that data does not have to be painful, and a vendor may be a viable option for both cleaning the data and helping you build good data practices.
What questions do I want to ask?
Regardless of whether regression analysis, classic statistical models you saw in college, or highly proprietary statistical models are used by your scientists using software or your analytics partner, you do not have to understand the entirety of the math involved. You do need to understand what question is being answered. You are no longer reporting who gave a gift over $1k or $100k, but rather who can give a major gift. That means that access to some data sources outside of your database may be necessary to determine both affinity and capacity. The model needs to know: to what other organizations did the donor give, and how much wealth does she possess?
What will you do with the information? Can your organization react to and act upon the predictions?
If you use a partner experienced in nonprofits, and you understood the questions you were asking, the predictions will make sense. The process of using predictive analytics is only a benefit if you use the results. Using the predictions requires a cohesive organization willing to change. As with any major initiative you must consider and plan for successful adoption. The culture of your organization trumps everything else!
Covariance and Correlation are two mathematical concepts which are quite commonly used in statistics. Both of these two determine the relationship and measures the dependency between two random variables. Despite, some similarities between these two mathematical terms, they are different from each other. Correlation is when the change in one item may result in the change in the another item. On the other hand, covariance is when two items vary together. Read the given article to know the differences between covariance and correlation.
Key Differences Between Covariance and Correlation
The following points are noteworthy so far as the difference between covariance and correlation is concerned:
A measure used to indicate the extent to which two random variables change in tandem is known as covariance. A measure used to represent how strongly two random variables are related known as correlation.
Covariance is nothing but a measure of correlation. On the contrary, correlation refers to the scaled form of covariance.
The value of correlation takes place between -1 and +1. Conversely, the value of covariance lies between -∞ and +∞.
Covariance is affected by the change in scale, i.e. if all the value of one variable is multiplied by a constant and all the value of another variable are multiplied, by a similar or different constant, then the covariance is changed. As against this, correlation is not influenced by the change in scale.
Correlation is dimensionless, i.e. it is a unit-free measure of the relationship between variables. Unlike covariance, where the value is obtained by the product of the units of the two variables.
Conclusion
Both measures only linear relationship between two variables, i.e. when the correlation coefficient is zero, covariance is also zero. Further, the two measures are unaffected by the change in location.
Correlation is a special case of covariance which can be obtained when the data is standardized. Now, when it comes to making a choice, which is a better measure of the relationship between two variables, correlation is preferred over covariance, because it remains unaffected by the change in location and scale, and can also be used to make a comparison between two pairs of variables.
Machine learning, very simply put, is applications based on prediction using models. Building systems that predict is hard and validating them is even harder.
To best illustrate this, an excellent use case is in the medical industry where machine learning systems are used for DNA analysis to determine participating candidates for research treatments. The input data in this case are the DNA sequences that are constantly refined based on the data that the medical industry gathers. The outputs are the DNA sequences of patients who will benefit most from the research treatments.
These systems are based on learning algorithms, which change over time based on the learning data and number of iterations. Hence from a testing standpoint, the results for a fixed set of input will change as we learn more about the inputs.
Traditional testing techniques are based on fixed inputs. Testers are hard-wired to believe, that given inputs x and y, the output will be z and this will be constant until the application undergoes changes. This is not true in machine learning systems. The output is not fixed. It will change over time as we know more and as the model on which the machine learning system is built evolves as it is fed more data. This forces the testing professional to think differently and adopt test strategies that are very different from traditional testing techniques.
Mentioned below are critical activities that I believe will be essential to test machine learning systems:
1. Developing training data sets: This refers to a data set of examples used for training the model. In this data set, you have the input data with the expected output. This data is usually prepared by collecting data in a semi-automated way.
2. Developing test data sets: This is a subset of the training dataset that is intelligently built to test all the possible combinations and estimates how well your model is trained. The model will be fine-tuned based on the results of the test data set.
3. Developing validation test suites based on algorithms and test datasets. Taking the DNA example, test scenarios include categorizing patient outcomes based on DNA sequences and creating patient risk profiles based on demographics and behaviors.
4. The key to building validation suites is to understand the algorithm. This is based on calculations that create a model from the training data. To create a model, the algorithm analyzes the data provided, looks for specific patterns, and uses the results of this analysis to develop optimal parameters for creating the model. The model is refined as the number of iterations and the richness of the data increase.
Some algorithms in popular use are regression algorithms that predict one or more continuous numeric variables such as return on investment. Another example is the association of algorithms that create co-relations based on attributes of a data set. This is used for portfolio analysis in capital markets. Another illustration in digital applications is sequence algorithms that predict customer behavior based on a series of clicks or paths on a digital platform.
5. Communicating test results in statistical terms. Testers are traditionally used to expressing the results of testing in terms of quality such as defect leakage or severity of defects. Validation of models based on machine algorithms will produce approximations and not exact results. The testing community will need to determine the level of confidence within a certain range for each outcome and articulate the same.
In summary, software testing will be one of the most critical factors that determine the success of a machine learning system. Just like the models that we test, the hypothesis that holds true today may change tomorrow. The must-have skills that the test professional will need are critical thinking, an engineering mindset, and constant learning.
Machine Learning in Test Automation:
The goals we are trying to achieve here by using Machine Learning for automation in testing are to dynamically write new test cases based on user interactions by data-mining their logs and their behavior on the application / service for which tests are to be written, live validation so that in case if an object is modified or removed or some other change like “modification in spelling” such as done by most of the IDE’s in the form of Intelli-sense like Visual Studio or Eclipse.
Machine Learning in “Test Automation” can help prevent some of the following but not limited cases:
1) Saving on Manual Labor of writing test cases
2) Test cases are brittle so when something goes wrong a framework is most likely to either drop the testing at that point or to skip some steps which may result in wrong / failed result.
3) Tests are not validated until and unless that test is run. So, if a script is written to check for an “OK” button then we wouldn’t know about its existence until we run the test.
The Machine Shall help recover from tests on the fly by applying fuzzy matching, that means if an object gets modified or removed then the program then the script must be able to find the closest object to the one it was looking for and then continue the test. For example, if a web services has options “small, medium, large” at first and the script was written according to that and if another choice i.e. “extra-large” is added then the script must be able to adapt to that and anticipate that change so that the test run can continue running without fail.
HP Unified Function Testing is one of the well-known tools available in the market used for automated testing. It has a GUI interface for the same, other than that there are other tools like selenium libraries (implemented in several languages like Java, C++, C#, Python etc.) and Cucumber. Tools like these allow one to write their scripts and let the scripts take the job of testing from there by running through several cases.
Ideas for Implementation
Before starting the tests the system needs to learn the cases. We need to give it something to begin with. Before triggering the training part, we had to setup the system where some ads where shown to the normal users in a customized window of time, and during that time logs were collected and recorded which helped us in generating a gender ratio and age groups of people who looked at specific ads. The goal was to find out which age group and gender of users were stimulated to purchase something from the website after looking at certain ads presented to them. The results were saved as training data so that tests could be performed on them.
The machine was trained to write test cases based on the collected information. Training data was updated every once in a while so that tests could be run on the latest data based on different demographics and relevant ads could be delivered to potential customers. Had this been done manually one might have to make modifications in the script or add test cases manually each time trends changes or the website changes.
ML algorithms for automated testing
SVM: It belongs to the “linear classifier” family of ML algorithms that attempt to find a (linear) hyperplane that separates examples from different classes. In the learning phase, SVM treats the training data as a vector of k-1 dimensions. And the goal is to find maximum margin (distance). SVM technique is mostly used for the binary classification. Other than this we have MartiRank, a ranking algorithm, in the learning phase. It takes a number of rounds and during each round/iteration data is broken down into N sub-lists, each sub-list containing 1/n of the total number of device / app failures.
In case of Regression testing a suite of test cases needed to be developed, development of MartiRank is an ongoing process and has been used to detect new bugs. Ex: A dev might have refactored some code in the application and put into a new function. Regression testing showed us that the resulting models were different from the previous ones.
When we write test cases we test how the software is supposed to behave theoretically and there’s no real data with us, some of the test cases might never be used in real life and some that missed the test cases might be the most important ones and that is why data-mining the logs and letting the machine write test cases according to those logs automatically saves a lot of man-hours and helps in practical testing. Services like HockeyApp & TestFlight are providing automated mobile app testing as a service.
As for GUI tests there are some research papers out there that talk about Deep Learning and Reinforcement Learning for automation of the test. The systems that were being tested were first data-mined to get the meaningful clicks, texts and button pushes on the GUI interface which generated a good amount of training data. That data was then used to perform tests on the software for a few hours. Best part was that there were no need for models or test cases to be written and the bugs were being found as the time passed by, but some of the cases were not being tested which can be due to lack of training data. The reinforcement approach improved the testing as they were running through multiple iterations.
Intel and Nvidia have been investing heavily in hardware solutions that can aid Deep Learning and related algorithms to achieve results more quickly. Moving from a mobile first world to an AI first world. We know that for testing a certain product whether that be a small calculator there can never be enough number of right test cases and that is why developers and testers are encouraged to write more and more test cases in order to make their product more stable. Paul Graham once suggested the used of Bayesian Filter for filtering out spam emails, thousands of emails were fed to the system and it was made to learn then tests were performed on that training data to make sure that the filter was fool-proof. Web crawlers move through different websites looking for 404 or other errors all the time, updating their indexes and updating their test cases in real time