Data science is all about trying to create a process that allows you to chart out new ways of thinking about problems that are novel, or trying to use the existing data in a creative atmosphere with a pragmatic approach.
Businesses are struggling to grapple with the phenomenal information explosion. Conventional database systems and business intelligence applications have given way to horizontal databases, columnar designs and cloud-enabled schemas powered by sharing techniques.
Particularly, the role of QA is very challenging in this context, as this is still in a nascent stage. Testing Big Data applications requires a specific mindset, skillset and deep understanding of the technologies, and pragmatic approaches to data science. Big Data from a tester’s perspective is an interesting aspect. Understanding the evolution of Big Data, What is Big Data meant for and Why Test Big Data Applications is fundamentally important.
Big Data Testing – Needs and Challenges
The following are some of the needs and challenges that make it imperative for Big Data applications to be tested thoroughly.
An in-depth understanding of the 4 Nouns of Big Data is a key to successful Big Data Testing.
- Increasing need for Live integration of information: With multiple sources of information from different data, it has become imminent to facilitate live integration of information. This forces enterprises to have constantly clean and reliable data, which can only be ensured through end-to-end testing of the data sources and integrators.
- Instant Data Collection and Deployment: Power of Predictive analytics and the ability to take Decisive Actions have pushed enterprises to adopt instant data collection solutions. These decisions bring in significant business impact by leveraging the insights from the minute patterns in large data sets. Add that to the CIO’s profile which demands deployment of instant solutions to stay in tune with changing dynamics of business. Unless the applications and data feeds are tested and certified for live deployment, these challenges cannot be met with the assurance that is essential for every critical operation.
- Real-time scalability challenges: Big Data Applications are built to match the level of scalability and monumental data processing that is involved in a given scenario. Critical errors in the architectural elements governing the design of Big Data Applications can lead to catastrophic situations. Hardcore testing involving smarter data sampling and cataloging techniques coupled with high end performance testing capabilities are essential to meet the scalability problems that Big Data Applications pose.

Current data integration platforms which have been built for an older generation of data challenges, limit IT’s ability to support the business. In order to keep up, organizations are beginning to look at next-generation data integration techniques and platforms.
Ability to understand, analyze and create test sets that encompass multiple data sets, is vital to ensure comprehensive Big Data Testing.





 Start with learning the
Start with learning the 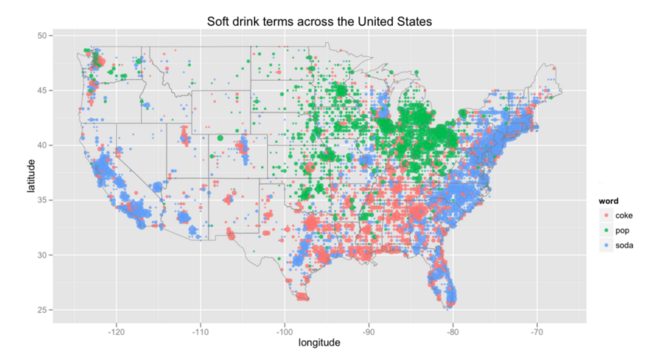
 The first is
The first is 


